
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 중국수출통제
- 파이썬배우기
- SQL
- 스위스기준금리
- 노르웨이기준금리
- 파이썬강의후기
- 셀레니움
- 미국디리스킹
- 파이썬기초
- swift문법
- 파이썬문법
- 파이썬강의
- 광교카페
- 패스트캠퍼스수강후기
- 파이썬인강
- MBTI성격유형
- 비트코인
- MBTI
- 파이썬수업
- 파이썬독학하기
- MBTI성격검사
- 패스트캠퍼스후기
- 파이썬클래스
- 파이썬온라인수업
- 파이썬독학
- 순천여행
- 비전공자파이썬
- 스크래핑
- 암호화폐
- 파이썬 인강
- Today
- Total
이제 데이터 공부 안하는 블로그
[패스트캠퍼스 수강 후기] 파이썬 인강 100% 환급 챌린지 20회차 미션 본문

어제 웹툰을 페이지에 있는 내용들을 스크래핑 했었는데요,
이부분을 계속해서 학습하겠습니다.
웹툰 페이지에 보면 웹툰 순위가 있습니다. 이부분을 스크래핑 해보겠습니다.
rank1 이라는 변수를 선언해서 가져오겠습니다.
크롬에서 개발자도구를 통해 살펴보면 1위인 웹툰은 li태그에서 class가 rank01이라는 이름으로 되어있습니다.
rank1 = soup.find("li", attrs={"class":"rank01"})
이렇게 해주면 1위 웹툰을 가져 오게됩니다.
웹툰을 제목을 보고 싶다면
print(rank1.a.get_text())
라고 코딩해주면 제목만 나오게 됩니다.
이어서 2위인 웹툰을 알고 싶다면 next_sibling이라는 명령으로 가져올수 있습니다.
rank2 = rank1.next_sibling
rank1의 다음 형제를 가져오라는 명령이 됩니다.
print(rank2.a.get_text())
라고 써주면 2위인 웹툰을 볼수 있을까요??
나오지 않습니다. 아마도 줄바꿈이라든지 빈줄이라든지 하는 내용이 있는듯합니다.
next_sibling을 한번더 써주면 됩니다.
rank2 = rank1.next_sibling.next_sibling
print(rank2.a.get_text())
이렇게 해주면 2위의 웹툰 제목이 출력됩니다.
다음 웹툰 뿐만아니라 앞의 웹툰 제목도 뽑아낼수 있습니다.
next의 반대는? previous죠.
rank1 = rank2.previous_sibling.previous_sibling
print(rank1.a.get_text())
해주면 다시 1위의 웹툰 제목 을 볼수 있습니다.
2위의 제목을 뽑아낼수 있는 다른방법도 있습니다.
next_silbing을 두번써주지 않고도 find 명령을 통해 찾을수도 있습니다.
rank2= rank1.find_next_sibling("li")
print(rank2.a.get_text())
이렇게 beautifulsoup을 사용하면 아주 쉽고 편리하게 원하는 데이타를 찾아 가져올수가 있습니다.
find_all
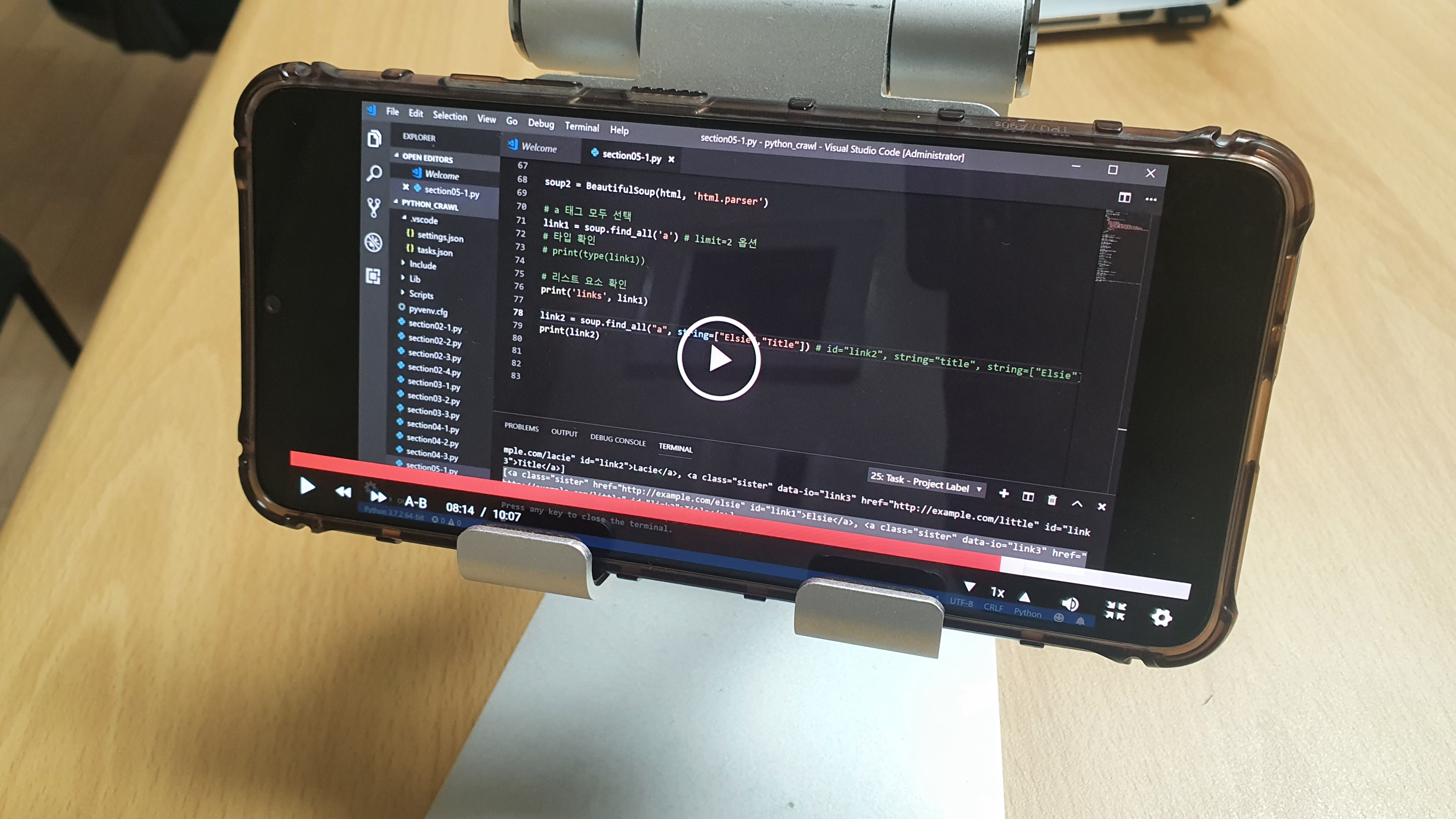
이번에는 find_all을 사용해서 네이버 웹툰에서 전체 목록 가져오기를 해보았습니다.
find 함수만 사용하면 그 조건에 해당하는 첫번째 엘리먼트만 찾아주고
find_all을 사용하면 그 조건에 해당하는 모든 엘리먼트를 찾아줍니다.
cartoons = soup.find_all(“a”, attras={“class”:”title”})
# soup 전체 중에서 태그명이 a 이고 class 속성이 title인 a 엘리먼트를 모두 찾아서 임의로 만든 cartoons 라는 변수에 넣어줍니다.
이제 반복문을 통해서 결과값을 출력해보도록 하겠습니다.
for cartoon in cartoons:
print(cartoon.get_text())
# soup 전체 중에서 태그명이 a 이고 class 속성이 title인 a 엘리먼트를 모두 찾아서 출력해줍니다.
'파이썬' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 파이썬 인강 100% 환급 챌린지 22회차 미션 (0) | 2020.11.23 |
|---|---|
| [패스트캠퍼스 수강 후기] 파이썬 인강 100% 환급 챌린지 21회차 미션 (0) | 2020.11.22 |
| [패스트캠퍼스 수강 후기] 파이썬 인강 100% 환급 챌린지 19회차 미션 (0) | 2020.11.20 |
| [패스트캠퍼스 수강 후기] 파이썬 인강 100% 환급 챌린지 18회차 미션 (0) | 2020.11.19 |
| [패스트캠퍼스 수강 후기] 파이썬 인강 100% 환급 챌린지 17회차 미션 (0) | 2020.11.18 |



