
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 비트코인
- 파이썬클래스
- MBTI
- 파이썬강의후기
- 셀레니움
- 스위스기준금리
- swift문법
- 패스트캠퍼스수강후기
- 노르웨이기준금리
- 파이썬강의
- 파이썬온라인수업
- 비전공자파이썬
- 파이썬인강
- 미국디리스킹
- 파이썬 인강
- 파이썬독학하기
- 암호화폐
- 파이썬독학
- 광교카페
- SQL
- MBTI성격검사
- 파이썬문법
- 파이썬배우기
- 중국수출통제
- MBTI성격유형
- 파이썬수업
- 스크래핑
- 순천여행
- 패스트캠퍼스후기
- 파이썬기초
- Today
- Total
이제 데이터 공부 안하는 블로그
Fast Text - 철자 단위 임베딩(Character level Embedding) 본문
OOV(Out of Vocabulary) 문제
아무리 열심히 크롤링을 해서 데이터 수집을 한다고 하더라도 세상의 모든 단어가 포함된 말뭉치를 만드는 것은 불가능하다. word2vec은 말뭉치에 등장하지 않은 단어에 대해서 임베딩 벡터를 만들지 못한다는 단점이 있다. 이렇게 기존 말뭉치에 없는 단어가 등장하는 문제를 OOV(Out of Vocabulary) 문제라고 한다. 또한 적게 등장하는 단어에 대해서는 학습이 적게 일어나기 때문에 적절한 임베딩 문제를 생성하지 못한다는 것도 word2vec의 단점이다.
이러한 문제를 해결하기 위해서 FastText가 등장했다. FastText 또한 Word2Vec와 마찬가지로 단어를 벡터로 만드는 방법 중 하나인데, Word2vec와의 가장 큰 차이점이라면 Word2vec는 단어를 쪼개질 수 없는 단위로 생각하고, FastText는 하나의 단어 안에 여러 단어들이 존재하는 것으로 간주해서 학습한다는 점이다.

FastText에서는 각 단어를 글자 단위 n-gram의 구성으로 본다. 여기서 n-gram이란 연속적인 단어 나열을 의미한다. n을 몇으로 결정하는지에 따라서 단어들이 어떻게 분리되는지가 결정된다. 만약 n을 3로 설정한 경우, 'eating'라는 문자열은 3개의 단어(알파벳)으로 묶이게 된다. 단어를 3개로 묶기 이전에 모델이 접두사와 접미사를 인식할 수 있도록 단어 앞뒤로 <, > 를 붙여주고 임베딩을 적용한다. 그러면
- <ea
- eat
- ati
- tin
- ing
- ng>
로 분리되어 이것들이 벡터로 만들어지게 된다. FastText는 n을 3 ~ 6개로 설정하기 때문에 위와 같이 단어를 분리하는 과정을 n = 3 부터 n = 6 까지 진행하면 총 18개의 벡터를 구할 수 있다.
| 단어 | n의 길이 설정 | Character n-grams |
| eating | 3 | <ea, eat, ati, tin, ing, ng> |
| eating | 4 | <eat, eati, atin, ting, ing> |
| eating | 5 | <eati, eatin, ating, ting> |
| eating | 6 | <eatin, eating, ating> |
eating 이라는 단어가 말뭉치 내에 있다면 skip-gram으로부터 학습한 임베딩 벡터에 위에서 얻은 18개 Character-level n-gram 들의 벡터를 더해준다. 하지만 eating 이라는 단어가 말뭉치에 없다면 18개 Character-level n-gram 들의 벡터만으로 구성한다.
아래 그림은 X, Y 축에 있는 단어 내 character n-gram 에 대해 서로의 연관관계를 나타낸 그래프로 빨간색일 수록 단어들의 유사관계가 높음을 나타낸다.

위 그래프에서는 "ity>" 와 "ness>" 가 상당히 유사한 관계를 보이는 것을 확인할 수 있다. 실제로 둘은 모두 명사를 나타내기 위한 접미사이다. FastText는 이렇게 단어의 문법적 구조를 잘 나타낸다는 특징을 가지고 있다.
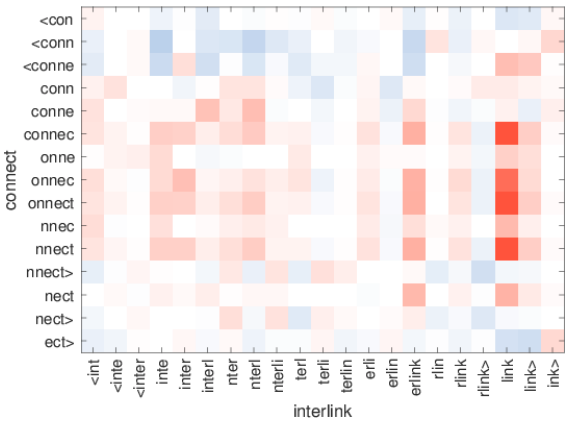
위 그래프에서는 "link" 와 "nnect, onnect, connec" 등이 상당히 유사한 관계에 있음을 보여준다. connect와 link가 가지고 있는 "연결하다"라는 의미를 n-gram 임베딩 벡터도 유사하게 가지고 있음을 확인할 수 있다.
gensim 패키지로 fastText 실습하기

위와 같이 모델을 만들어 학습을 진행시키고, electrofishing에 대해서 유사 단어를 찾아 보았다.

Word2Vec는 학습하지 않은 단어에 대해서 유사한 단어를 찾아내지 못한 반면, FastText는 유사한 단어를 계산해서 찾아내는 것을 볼 수 있다.
참고자료 : https://wikidocs.net/22883
'딥러닝' 카테고리의 다른 글
| LSTM (Long Term Short Memory, 장단기기억망) & GRU (Gated Recurrent Unit) (0) | 2021.08.19 |
|---|---|
| 순환 신경망 (Recurrent Neural Network, RNN) (0) | 2021.08.19 |
| 분산 표현(Distributed representation) (0) | 2021.08.18 |
| 자연어처리(NLP, Natural Language Processing) (0) | 2021.08.17 |
| 신경망 학습 최적화 방법 Optimization (0) | 2021.08.12 |



