
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬강의
- 파이썬 인강
- 패스트캠퍼스수강후기
- 파이썬독학하기
- 노르웨이기준금리
- 중국수출통제
- MBTI성격유형
- 암호화폐
- SQL
- 미국디리스킹
- 셀레니움
- MBTI
- 광교카페
- 스위스기준금리
- 파이썬배우기
- swift문법
- 파이썬강의후기
- 파이썬클래스
- 파이썬기초
- 파이썬수업
- 순천여행
- 스크래핑
- 비트코인
- 비전공자파이썬
- MBTI성격검사
- 파이썬온라인수업
- 파이썬인강
- 패스트캠퍼스후기
- 파이썬독학
- 파이썬문법
- Today
- Total
이제 데이터 공부 안하는 블로그
순환 신경망 (Recurrent Neural Network, RNN) 본문
* 제가 공부하기 위해 만든 자료입니다. 혹시 틀린 부분이 있다면 댓글로 알려주시면 수정하겠습니다.
순환 신경망 (RNN, Recurrent Neural Network)
RNN은 연속형(Sequential) 데이터를 잘 처리하기 위해 고안된 신경망이다. 연속형(Sequential) 데이터란 순차적인 데이터로 어떤 순서로 오느냐에 따라서 단위의 의미가 달라지는 데이터를 말한다. 예를 들어 I work at google (나는 구글에서 일한다) 라는 문장에서는 work는 '일한다' 라는 의미의 동사로 쓰이고 google은 '구글 회사' 라는 의미의 명사로 쓰인다. 하지만 I google at work (나는 회사에서 구글링을 한다) 라는 문장에서 google은 '구글링한다' 라는 동사로 쓰이고 work는 '일터, 회사'라는 의미의 명사로 쓰인다. 이렇게 순서가 의미를 부여하는 데이터를 잘 처리하기 위해 고안된 신경망이 RNN이다.
RNN 구조

RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 이 출력을 다시 입력으로 보내는 특징을 갖고 있다. 이렇게 출력 벡터가 다시 입력되는 특성 때문에 순환신경망 이라는 이름이 붙여졌다.
RNN 계층은 그 계층으로의 입력 벡터와, 바로 그 전에 있는 RNN 계층의 출력 벡터를 받아들인다. 입력된 두 벡터를 바탕으로 아래 식과 같이 출력을 계산한다.
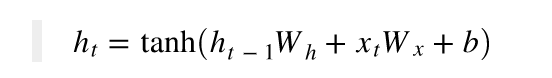
현재 시점을 변수 t로 표현한다고 가정할 때, 현재 시점 t에서 RNN셀이 갖고 있는 값은 과거 RNN 셀값에 영향을 받는다. RNN 셀이 출력층 방향으로 또는 다음 시점 t+1의 자신에게 보내는 값을 은닉 상태(hidden state)라고 한다. 즉, t 시점의 RNN셀은 t-1 시점(즉, t 한 단계 전 시점)의 RNN셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력값으로 사용한다.
다양한 형태의 RNN
다양한 형태의 RNN과 각각의 RNN이 어떤 분야에 사용되는지 알아보자. (맨 왼쪽의 one to one은 순환이 적용되지 않는 형태이다.)

- one-to-many : 1개의 벡터를 받아 Sequential한 벡터를 반환합니다. 이미지를 입력받아 이를 설명하는 문장을 만들어내는 이미지 캡셔닝(Image captioning)에 사용됩니다.
- many-to-one : Sequential 벡터를 받아 1개의 벡터를 반환합니다. 문장이 긍정인지 부정인지를 판단하는 감성 분석(Sentiment analysis)에 사용됩니다.
- many-to-many(1) : Sequential 벡터를 모두 입력받은 뒤 Sequential 벡터를 출력합니다. 시퀀스-투-시퀀스(Sequence-to-Sequence, Seq2Seq) 구조라고도 부릅니다. 번역할 문장을 입력받아 번역된 문장을 내놓는 기계 번역(Machine translation)에 사용됩니다.
- many-to-many(2) : Sequential 벡터를 입력받는 즉시 Sequential 벡터를 출력합니다. 비디오를 프레임별로 분류(Video classification per frame)하는 곳에 사용됩니다.
RNN의 단점
- 단점 1 : 벡터가 순차적으로 입력되기 때문에 병렬화가 불가능하다는 단점이 있다. (병렬화는 동일한 처리를 다수의 데이터에 적용하는 방식을 말한다.)
- 단점 2 : 기울기 소실, 기울기 폭발 문제
입력층에 가까운 층들에서 기울기가 점차적으로 작아지는 현상이 발생한다. 결국 입력층에서 가까운 층들에서 가중치가 업데이트가 제대로 되지 않아서 최적의 모델을 찾을 수 없는 현상을 기울기 소실이라고 한다. 반대로 기울기가 점차 커지면서 가중치들이 비정상적으로 큰 값이 되어 발산하는 경우는 기울기 폭발이라고 한다.
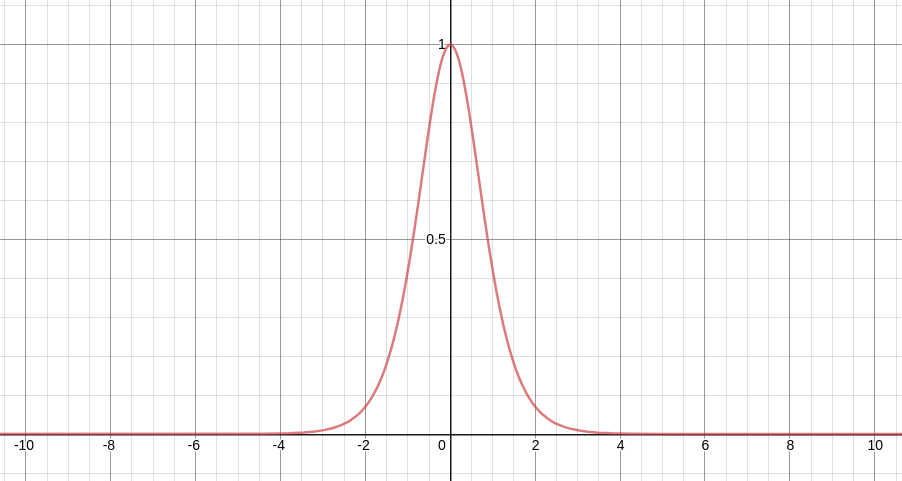
역전파 과정에서 RNN의 활성화 함수인 tanh의 미분값을 전달하게 된다. 위의 그래프는 tanh를 미분한 함수는 위와 같이 생겼다. 위 그래프를 살펴보면 최대값은 1이고 -4, 4 사이 이외의 범위에서는 거의 0의 가까운 값을 나타내는 것을 볼 수 있다. 문제는 역전파 과정에서 이 값을 반복해서 곱해주어야 한다는 점이다.
이 과정이 10회 반복된다고 보면, 이 값의 10 제곱이 식 내부로 들어가게 된다. 만약 이 값이 0.9 일 때 10제곱이 된다면 0.349가 된다. 이렇게 되면 시퀀스 앞쪽에 있는 hidden-state 벡터에는 역전파 정보가 거의 전달되지 않게 된다. 이런 문제를 기울기 소실(Vanishing Gradient)이라고 한다.
반대로 이 값이 1.1 이면 10제곱만해도 2.59배로 커지게 된다. 이렇게 되면 시퀀스 앞쪽에 있는 hidden-state 벡터에는 역전파 정보가 과하게 전달된다. 이런 문제를 기울기 폭발(Exploding Gradient)이라고 한다.
위와 같은 RNN의 단점을 보완하기 위해 고안된 것이 장단기 기억망(Long-Short Term Memory, LSTM) 이다.
'딥러닝' 카테고리의 다른 글
| 어텐션(Attention) (0) | 2021.08.21 |
|---|---|
| LSTM (Long Term Short Memory, 장단기기억망) & GRU (Gated Recurrent Unit) (0) | 2021.08.19 |
| Fast Text - 철자 단위 임베딩(Character level Embedding) (0) | 2021.08.18 |
| 분산 표현(Distributed representation) (0) | 2021.08.18 |
| 자연어처리(NLP, Natural Language Processing) (0) | 2021.08.17 |



