
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 파이썬독학하기
- 파이썬강의후기
- 파이썬기초
- MBTI성격유형
- 파이썬문법
- 암호화폐
- 중국수출통제
- MBTI
- 파이썬배우기
- 셀레니움
- 파이썬강의
- 파이썬온라인수업
- swift문법
- 파이썬인강
- SQL
- 미국디리스킹
- 파이썬독학
- 순천여행
- 파이썬수업
- 파이썬 인강
- 파이썬클래스
- 스위스기준금리
- 패스트캠퍼스수강후기
- 광교카페
- 비트코인
- 비전공자파이썬
- 스크래핑
- 패스트캠퍼스후기
- MBTI성격검사
- 노르웨이기준금리
- Today
- Total
이제 데이터 공부 안하는 블로그
Transformer & BERT, GPT 본문
Seq2Seq 모델은 고정된 크기의 context vector를 사용하기 때문에 문장이 길어질 경우 문장 전체를 고정된 벡터 안에 다 담을 수 없다는 문제점과 기울기 소실의 문제점이 있었다. 그러한 문제를 해결하기 위해 2015년에 attention 기법을 소개하는 논문이 등장했고, 이후 transformer 의 등장으로 아예 RNN 사용하지 않고 오직 attention만으로도 훨씬 좋은 성능을 낼 수 있는 모델이 가능하다는 것을 알게 되었다. transformer 등장 이후에는 더 이상 RNN을 사용하지 않고 attention 메커니즘을 활용하여 입력 시퀀스 전체에서 정보를 추출하는 방향으로 연구가 발전되어 왔다고 한다. 2021년 기준으로 기계 번역 고성능 모델들은 주로 transformer 아키텍처를 기반으로 하고 있다.
트랜스포머는 RNN을 사용하지 않지만 기존의 seq2seq 모델처럼 입력 시퀸스를 입력받고, 디코더에서 출력 시퀸스를 출력하는 인코터-디코더 구조를 유지하고 있다.

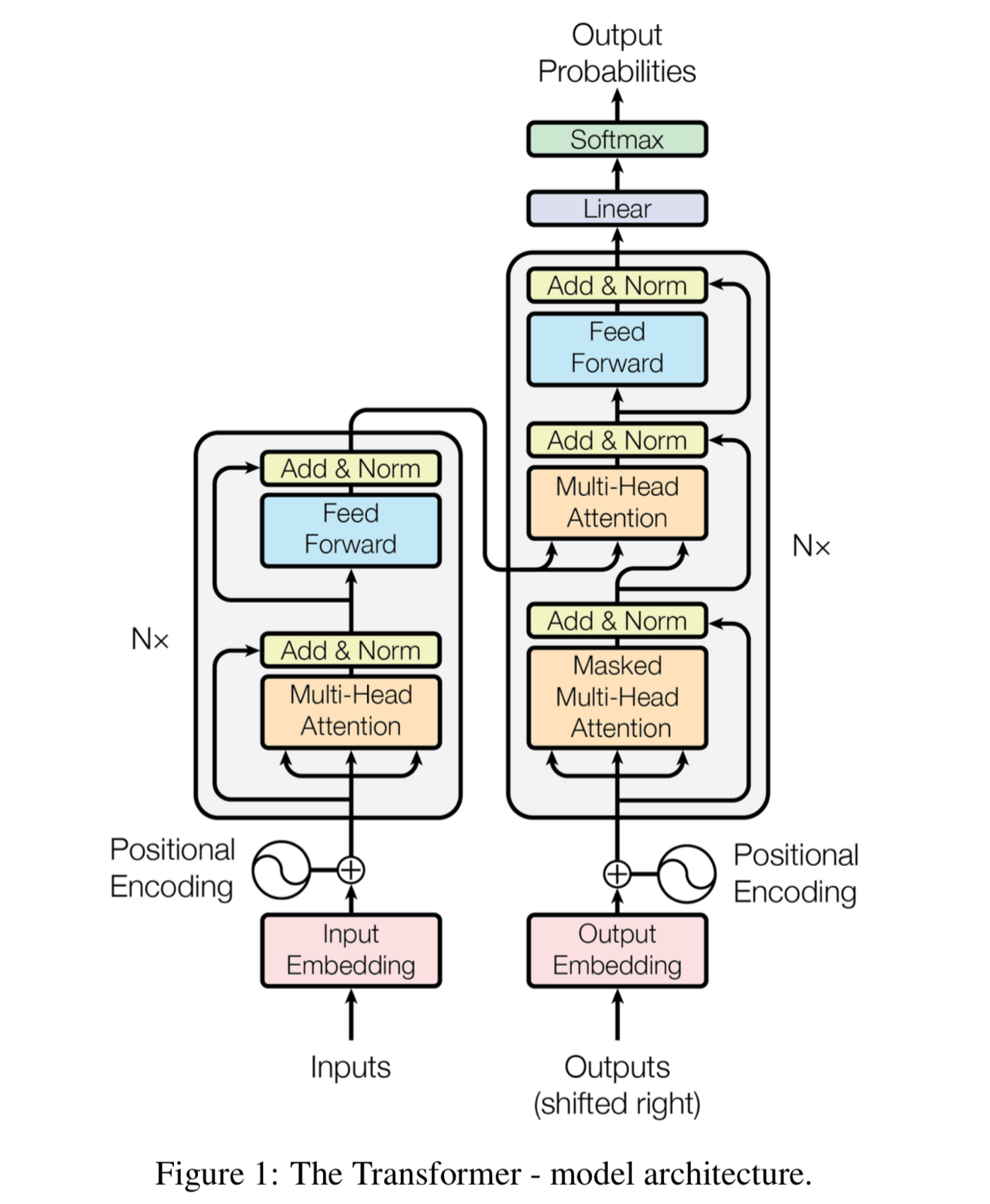
트랜스포머의 구조
트랜스포머의 인코더 블록은 크게 2개의 sub-layer [Multi-Head (Self) Attention, Feed Forward] 로 구성되어있고, 디코더 블록은 3개의 sub-layer [Masked Multi-Head (Self) Attention, Multi-Head (Encoder-Decoder) Attention, Feed Forward] 로 구성되어있다.
포지셔널 인코딩(Positional Encoding)
RNN이 순차적으로 단어를 입력받아서 처리했던 것과 다르게 트랜스포머는 단어 정보를 한번에 입력받기 때문에 각 단어의 위치 정보(position information)를 알 수 없다. 그래서 각 단어들의 위치정보를 알려주기 위해서 포지셔널 인코딩(positional encoding)이라는 것을 해주어야 한다. 각 단어의 임베딩 벡터에 위치 정보를 더하여 모델의 입력으로 사용할 수 있게 하는 것을 포지셔널 인코딩(positional encoding)이라고 한다.
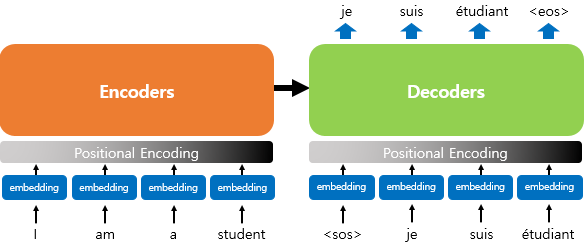
위의 그림과 같이 입력으로 사용되는 임베딩 벡터들에다가 포지셔널 인코딩 값을 더해준 후에 트랜스포머의 입력으로 사용한다.

위의 그림은 임베딩 벡터가 인코더의 입력으로 사용되기 전에 포지셔널 인코딩값이 더해지는 과정을 시각화한 것이다.
Self-Attention (셀프-어텐션)
셀프 어텐션은 트랜스포머의 주요 매커니즘이다.
'딥러닝' 카테고리의 다른 글
| Image Segmentation 이미지 분할 (0) | 2021.08.25 |
|---|---|
| Convolution Neural Network (CNN, 합성곱 신경망) (0) | 2021.08.24 |
| 어텐션(Attention) (0) | 2021.08.21 |
| LSTM (Long Term Short Memory, 장단기기억망) & GRU (Gated Recurrent Unit) (0) | 2021.08.19 |
| 순환 신경망 (Recurrent Neural Network, RNN) (0) | 2021.08.19 |



