
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- MBTI
- MBTI성격유형
- 광교카페
- 파이썬클래스
- MBTI성격검사
- 파이썬기초
- SQL
- 스위스기준금리
- 파이썬인강
- 비트코인
- 파이썬문법
- 노르웨이기준금리
- 스크래핑
- 미국디리스킹
- 파이썬강의
- swift문법
- 파이썬수업
- 패스트캠퍼스수강후기
- 순천여행
- 파이썬배우기
- 파이썬강의후기
- 패스트캠퍼스후기
- 파이썬독학
- 비전공자파이썬
- 파이썬독학하기
- 파이썬 인강
- 중국수출통제
- 셀레니움
- 파이썬온라인수업
- 암호화폐
- Today
- Total
이제 데이터 공부 안하는 블로그
Convolution Neural Network (CNN, 합성곱 신경망) 본문
* 제가 공부하기 위해 만든 자료입니다. 혹시 틀린 부분이 있다면 댓글로 알려주시면 수정하겠습니다.
Convolution Neural Network (CNN, 합성곱 신경망)
CNN은 이미지 처리에 뛰어난 성능을 보여주는 신경망이다.
CNN layer(합성곱 층)은 연산을 통해서 이미지의 특징을 추출하는 역할을 한다. 합성곱은 커널(kernel) 또는 필터(fileter) 라는 n x n 크기의 행렬로 높이(height) x 너비(width) 크기의 이미지를 처음부터 끝까지 겹치며 훑으면서 n x m 크기의 겹쳐지는 부분의 각 이미지와 커널의 원소의 값을 곱해서 모두 더한 값을 출력하는 것을 말한다.

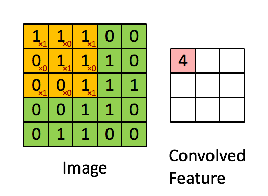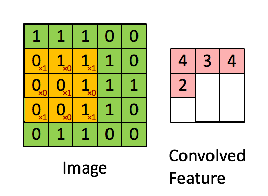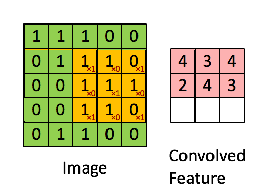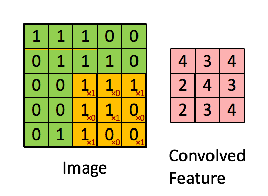
- Filter or Kernel : 가중치 (weights parameters)의 집합으로 이루어져 가장 작은 특징을 잡아내는 창
- Stride : 필터(filter)를 얼만큼씩 움직이며 이미지를 볼 지 결정하는 수 (예) Stride가 1이면 한칸씩 이동하며, 누락없이 모든것을 본다면, stride가 2 이면 한칸씩 건너뛰면서 Filter를 적용하게 되고, 띈 만큼 다음 레이어의 데이터의 수가 줄어든다.
위의 사진에서 노란색 3 x 3 격자 부분이 커널 or 필터 부분이다. 커널(kernel)은 일반적으로 3 × 3 또는 5 × 5를 사용한다. 초록색 격자 부분은 입력된 이미지라고 가정한다. 노란색의 커널이 이미지의 가장 맨 위 왼쪽부터 순차적으로 훑으면서 연산을 한다. 한 번의 연산을 1 스텝(step)이라고 한다. 위의 사진에서는 커널이 9번의 스텝에 걸쳐 작업을 하고 최종 결과 값으로 오른쪽 분홍색 그림과 같은 값을 출력했다. 이렇게 입력으로부터 커널을 사용하여 합성곱 연산을 통해 나온 결과를 특성 맵(feature map)이라고 한다.
위의 사진에서는 커널의 이동 범위가 한 칸이었지만, 사용자가 이동범위를 정할 수 있다. 이러한 이동 범위를 Stride 라고 한다.
(5 x 5 의 이미지에 3 x 3 의 커넬을 적용한 경우) Stride가 2일 경우에는 두칸씩 이동하기 때문에 위의 그림처럼 최종적으로 2 x 2의 특성 맵이 출력된다.

32 X 32 이미지를 5 x 5 필터 6개를 가지고 컨볼루션 연산을 수행하면 출력되는 맵의 크기(특징맵)는 필터가 6개 이기 때문에 32 x 32 x 6이 된다.
패딩(Padding)
위의 이미지들에서 알 수 있듯이 합성곱 연산 이후에는 특성 맵의 크기가 입력 크기보다 작아진다. 만약, 합성곱 층을 여러개 쌓았다면 최종적으로 얻은 특성 맵의 크기는 아주 작아지게 되버린다. 만약 특성 맵의 크기를 입력 크기와 동일하게 만들고 싶다면 패딩(padding) 작업을 해주면 된다.
패딩은 합성곱 연산을 하기 전에 입력의 가장자리에 지정된 개수의 폭만큼 행과 열을 추가해주는 것을 말한다. 주로 테두리를 0으로 채우는 제로 패딩(zero padding)을 많이 사용한다.
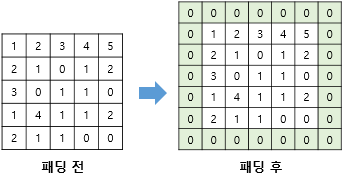
- Padding: Zeros(또는 다른 값)을 이미지의 외각(가장자리)에 배치하여 conv를 할 때 원래 이미지와 같은 데이터의 수를 갖을 수 있도록 도와줌 (Stride = 1일 때)
Pooling (풀링)
Pooling layer는 입력 데이터의 크기를 줄이는 역할을 한다. 이렇게 입력 데이터를 줄이는 이유는 계산량을 줄이고 과적합을 방지하기 위해서다. 컨볼루전 신경망에서는 많은 필터를 사용하기 때문에 데이터가 쉽게 커지고 과적합을 일으킬 수 잇기 때문에 Pooling 작업을 해준다.

Pooling은 Convolution lay를 resizing하여 새로운 layer를 얻는다. pooling layer 를 거치면 feature map의 차원을 더 줄일 수 있다. pooling에는 최댓값을 뽑아내는 max pooling, 평균값을 뽑아내는 mean pooling등 다양한 종류가 있지만 일반적으로 Max Pooling 을 많이 쓴다고 한다.
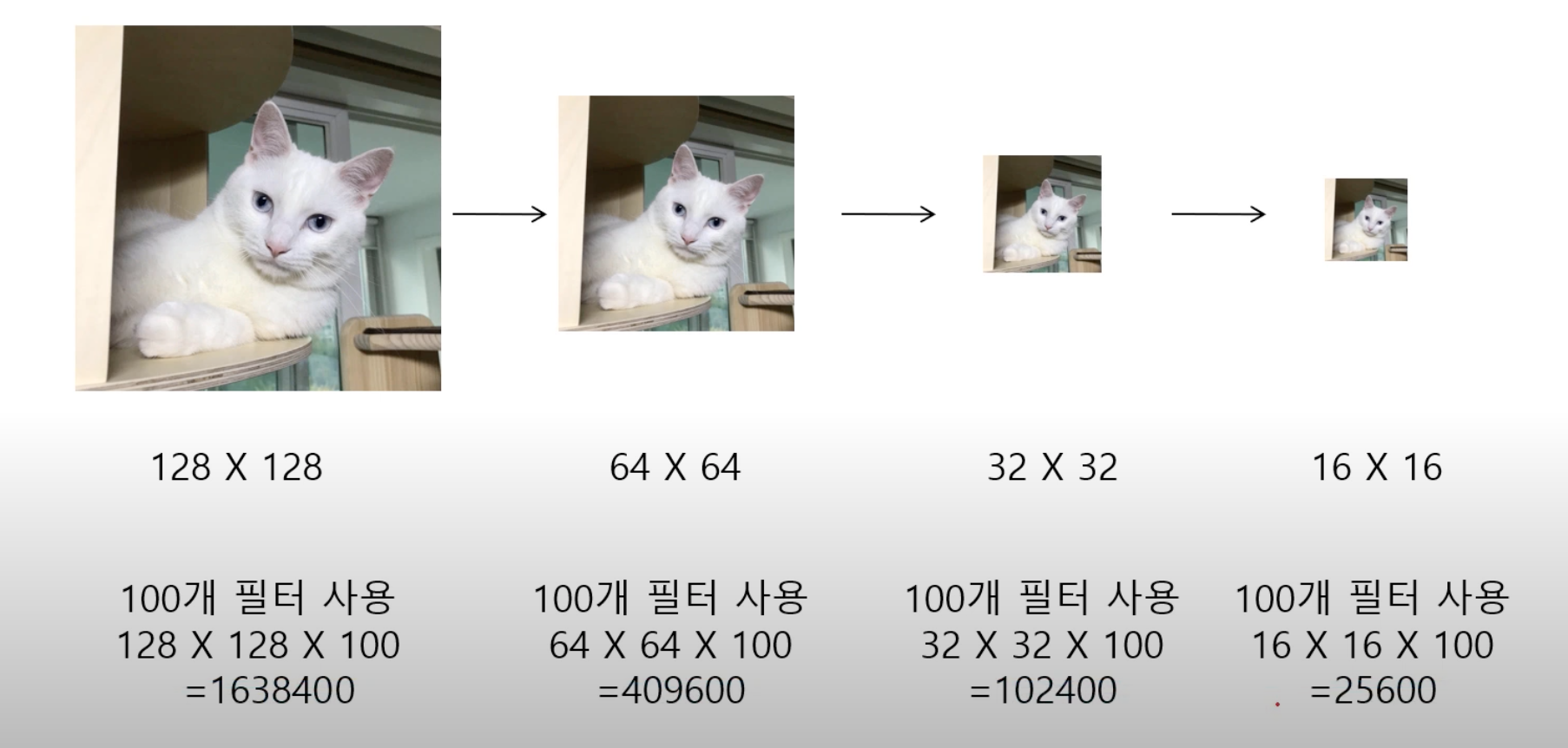
위와 같이 Pooling 과정은 이미지 데이터를 변형시키지 않고, 이미지의 중요 특징만 뽑아내서 작은 데이터로 출력해준다.
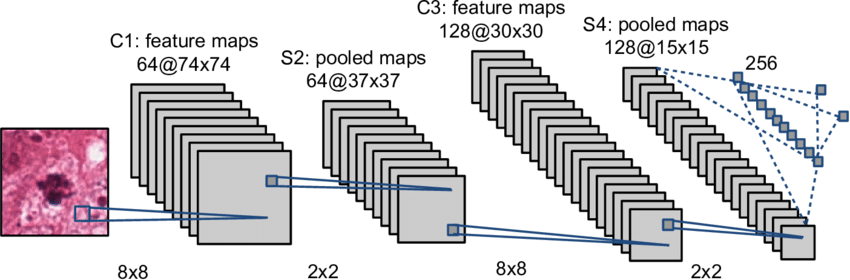

CNN은 여러개의 Convolution layer 와 Pooling layer 로 구성될 수 있다.

여러번의 Convolution 과 Pooling 작업 이후에는 flatten을 통해 이전 계층의 2차원 형태의 데이터를 1차원 벡터로 변환해서 기존 신경망에 전달해준다.
CNN을 사용하는 분야
- 사물인식 - Object Detection (YOLO) + RCNN(Fast, Faster, MASK RCNN)
- 포즈예측 - Pose Estimation (PoseNet)
- 윤곽분류 - Instance Segmentation (Detectron)
- 그 외에도 셀 수 없이 많다.
참고자료 : https://towardsdatascience.com/understand-the-architecture-of-cnn-90a25e244c7
Understand the architecture of CNN
In 2012, a revolution occurred: during the annual ILSVRC computer vision competition, a new Deep Learning algorithm exploded the records…
towardsdatascience.com
참고자료 : https://www.youtube.com/watch?v=WW4U_6H_yNI&list=PLwvr-xPygMX9Xd7zZmJNka9dPiFneKG_3&index=52
'딥러닝' 카테고리의 다른 글
| Image Segmentation 이미지 분할 (0) | 2021.08.25 |
|---|---|
| Transformer & BERT, GPT (0) | 2021.08.21 |
| 어텐션(Attention) (0) | 2021.08.21 |
| LSTM (Long Term Short Memory, 장단기기억망) & GRU (Gated Recurrent Unit) (0) | 2021.08.19 |
| 순환 신경망 (Recurrent Neural Network, RNN) (0) | 2021.08.19 |



